 570
570
 0
0
 2023-03-19
2023-03-19
 2023-03-19
2023-03-19
本次报告分享论文来自于2020年ieee transactions on neural networks and learning systems的“subject-independent brain–computer interfaces based on deep convolutional neural networks “,论文第一作者为oyeon kwon。
此论文主要最值得关注的贡献点是通过大规模运动想像数据集和多频谱-空间融合技术构建了一个subject-independent的脑机接口方法。论文中的subject-independent是指使得每个独立的用户都可以直接使用此系统,在使用前不进行额外的校准和解码的方法。
1. background
brain-computer interface(bci)是一种能够在人脑和外部设备之间建立直接通信途径的系统。近年来的研究表明,bci在通信、控制和康复的各种临床应用中显示出巨大潜力。在众多bci研究过程中,人们越来越关注脑电图(eeg)信号的分析,尤其是通过运动想象(motor imagery, mi)。这种兴趣是由于mi能够让健康人和残疾人在没有外部刺激的情况下自我调节大脑信号。在一般的bci系统中,由于每个人在每个时间段的生理和心理特征的差异,用户的大脑信号可能在几分钟、几小时或几天内发生变化。此外,大脑信号的空间来源、振幅变化和变异性都表现出主体的特定模式, 通俗而言就是因人而异。如果预计大脑信号偶尔会发生变化,那么在bci的普遍使用中,补偿大脑信号变化的解码方法是必不可少的。然而,不幸的是,校准过程是一项不方便且耗时的任务,大约需要20-30分钟才能建立一个可靠的解码器,所以在目前的bci研究中,校准过程是阻碍bci系统实际使用的障碍之一。解决这一问题可以降低bci的实际应用难度,为此作者做出了以下几项工作:
1.作者建立了一个大型的基于mi的eeg数据库,有54名健康受试者,每位受试者进行两轮实验。该数据库是迄今为止文献中报道的最大的mi bci数据集,它为深度学习(dl)架构(cnn)提供了足够数量的训练样本
2. 作者提出了一种新的鉴别性频谱空间输入形式,以代表不同受试者和会议的大脑信号模式的多样性。
3. 作者通过cnn模型应用空间融合技术,结合来自不同频率区域的光谱-空间输入完成对mi的有效分类。
2.large-scale mi-eeg dataset
作者提出大规模mi数据库的动机是为了捕捉不同受试者和不同时间的实验间出现的大幅度信号变化。
subject
在实验中,54名健康受试者(24-35岁:29名男性和25名女性)参加了两个时段的实验。其中,38名受试者从来没有进行过bci相关实验,其他受试者有bci实验经验。两次会议的间隔时间为1至2周。所有受试者都没有神经、精神或任何其他相关疾病史。实验开始时,受试者舒适地坐在椅子上,扶手距离20英寸液晶显示器60(±5)厘米(刷新率:60赫兹,分辨率:1600×1200)。在实验过程中,参与者被要求放松,尽量减少他们的眼睛和肌肉运动。这项研究得到了韩国大学机构审查委员会的批准(批准号为1040548-ku-irb-16-159-a-2),所有受试者都同意参与这项实验,并有书面同意书。
eeg recording
在本实验中,使用62个ag/agcl脑电图电极和4个emg电极记录脑电图数据,采样率为1000 hz。实验中使用brainamp作为放大器。脑电图通道以鼻根为参照物,并与电极fpz接地。脑电图/肌电图电极的配置和索引号见图1。
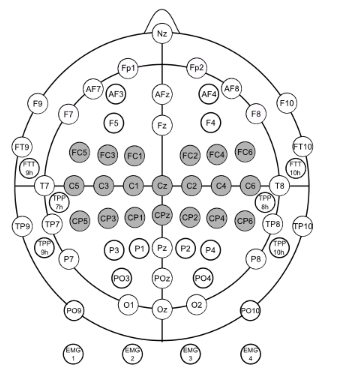
图一 所用电极分布
在整个实验过程中,脑电图电极的阻抗保持在10 kω以下,并在每个阶段开始前进行检查。基本上,在对eeg信号进行数字化之前,应用了一个抗混叠滤波器(antialiasing filter)。然后,对于低于40hz的的eeg信号数据通过奈奎斯特理论降频到100hz(这个是采样频率)。此外,为了验证性能,从运动皮层区域选择了20个电极(fc-5/3/1/2/4/6、c-5/3/1/z/2/4/6和cp-5/3/1/z/2/4/6),如图1中的灰色圆圈所示。
3.mi paradigm
在作者使用得mi范式中,所有受试者都被要求根据显示器上的视觉提示(左或右箭头)执行两类mi任务(左手或右手的运动想象)。在实验中,每次试验开始时,在显示器的中心有一个黑色的固定十字,为mi任务做准备,时间为3秒。之后,当显示器上出现左或右箭头时,受试者被指示执行mi任务4秒。每次mi任务后,屏幕保持空白6秒(±1.5)。这些整个程序是基于一般bci的实验设置。整个实验由一个离线(训练)和一个在线(测试)阶段组成。通过在离线阶段分析eeg数据可以获得csp的投影矩阵和基于csp和lda的分类模型,进一步而言,这些csp和lda参数被用于在线阶段的分析。在在线阶段,获得1.5秒的实时脑电数据,并以离线阶段使用的相同频段进行过滤。然后,离线阶段的csp投影矩阵被应用于在线eeg数据,然后,对数方差被作为特征。最后,lda参数被应用于这些特征并输出以左或右箭头的形式呈现给用户,作为实时视觉神经反馈。此外,我们在各阶段之间为个别参与者提供了灵活的休息时间。
4.频谱-空间特征表示方法(spectral –spatial feature representation, ssfr)
为了从大规模的mi数据集中创建一个通用的特征表示,作者主要关注并解决了以下问题:
1)如何从连续的eeg数据中提取鉴别性的erd模式,其中包括频率和空间领域的多样化的大脑信号。
2)如何从eeg epoch x(time samples × channels × trials)中构建适合输入cnn架构的m x m输入矩阵c。
3)如何设计一个cnn框架,以代表输入矩阵c的频谱-空间特征的多样性。
4.1 频谱-空间输入生成(spectral–spatial input generation)
让我们把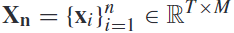 作为单次试验的eeg集合,让
作为单次试验的eeg集合,让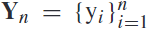 为匹配的类标签,其中n是eeg试验的数量,t是样本点的数量,m是通道的数量。
为匹配的类标签,其中n是eeg试验的数量,t是样本点的数量,m是通道的数量。
我们将b定义为一组预定义的频段,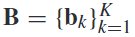 (例如,[8,30 hz],[11,20 hz],以此类推),其中k是频段的数量,细节见图2。然后,在刺激开始后的1000至3500毫秒之间,对单个受试者的过滤-脑电信号进行分割(即2500个数据样本×20个通道×200次试验)。
(例如,[8,30 hz],[11,20 hz],以此类推),其中k是频段的数量,细节见图2。然后,在刺激开始后的1000至3500毫秒之间,对单个受试者的过滤-脑电信号进行分割(即2500个数据样本×20个通道×200次试验)。
在作者提出的大规模mi数据库中,所有单次试验的eegs中, 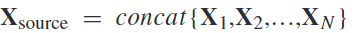 ,被依次从第一个受试者(n = 1)到最后一个受试者(n = 54)和匹配的类标签
,被依次从第一个受试者(n = 1)到最后一个受试者(n = 54)和匹配的类标签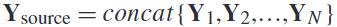 被依次连接起来,其中n是训练对象的数量。注意,目标主体(测试主体)总是被排除在训练之外。
被依次连接起来,其中n是训练对象的数量。注意,目标主体(测试主体)总是被排除在训练之外。
给定一定的频带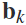 和串联的脑电信号
和串联的脑电信号 ,过滤后的脑电信号
,过滤后的脑电信号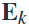 就可以被确定,如公式(1),其中
就可以被确定,如公式(1),其中 指频带滤波操作. 。
指频带滤波操作. 。
![]()
在基于预定义频段的带通滤波之后,利用标准的csp算法进行特征分析,如公式(2),其中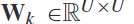 是通过计算广义特征向量问题从
是通过计算广义特征向量问题从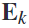 中分析得到的,而
中分析得到的,而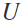 是要从csp算法中得到的空间滤波器的数量。在测量类之间的鉴别力之前,通过过滤后的eeg信号
是要从csp算法中得到的空间滤波器的数量。在测量类之间的鉴别力之前,通过过滤后的eeg信号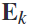 和空间滤波器
和空间滤波器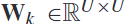 之间的矩阵乘法,得到每个频段
之间的矩阵乘法,得到每个频段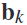 的特征向量。计算空间滤波信号的方差,然后,计算特征的对数
的特征向量。计算空间滤波信号的方差,然后,计算特征的对数 。
。
![]()
由于不确定哪些频段可以组成辨别性的大脑特征,作者用频段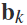 和特征
和特征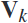 的互信息来编码这些不确定因素。互惠信息
的互信息来编码这些不确定因素。互惠信息![]() 是衡量两个随机变量之间的相互依赖性和随机变量的不确定性,计算方法如公式(3)
是衡量两个随机变量之间的相互依赖性和随机变量的不确定性,计算方法如公式(3)
![]()
其中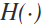 是熵,
是熵,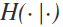 是条件熵。由于每个频段都有相互信息值,所以在图2中,频段
是条件熵。由于每个频段都有相互信息值,所以在图2中,频段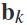 按互惠信息从大到小的顺序重新排列获得
按互惠信息从大到小的顺序重新排列获得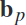 。作者认为这种方法将帮助发现可能有助于在大规模mi数据中判别erd的频段。在图2中重新排列的频段
。作者认为这种方法将帮助发现可能有助于在大规模mi数据中判别erd的频段。在图2中重新排列的频段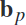 的基础上,频谱脑电信号
的基础上,频谱脑电信号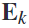 和空间滤波器
和空间滤波器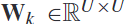 也根据新的频率顺序
也根据新的频率顺序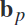 重新排列为
重新排列为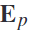 和
和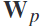 。从频谱和空间优化的eeg epoch(
。从频谱和空间优化的eeg epoch(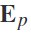 和
和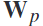 ),计算出协方差矩阵
),计算出协方差矩阵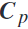 :
:

其中,输入集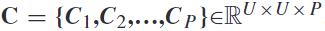 ,
,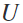 是空间滤波器的数量,
是空间滤波器的数量,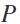 是频率索引的数量。
是频率索引的数量。
4.2. feature representation and fusion using cnn
在本节中,作者通过整合鉴别性的光谱-空间输入,提出了一个特征融合过程。我们的方法首先是利用多个频段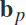 ,表1给出了作者具体选择的30个频段,
,表1给出了作者具体选择的30个频段,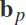 中的每个频率段代表了包含固有信息的erd模式的多样性。
中的每个频率段代表了包含固有信息的erd模式的多样性。
表1 论文中关注的频段

作者使用常规的cnn模型进行分类任务,不同的是整个cnn模型包含多个输入支流,每个输入都是按前文提出的方法处理后获得的协方差矩阵。它们经过cnn的特征提取,在模型的最后完成拼接,即池化压缩后的特征完成后端融合,如图2。
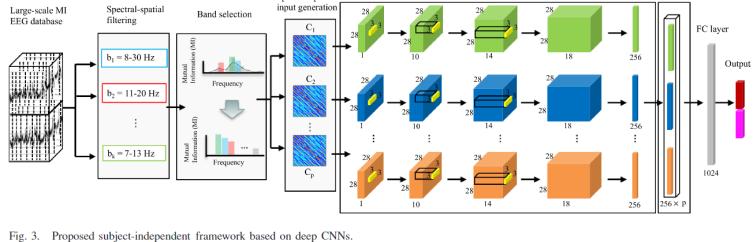
图1 基于cnn的频谱-空间融合脑电分析模型
5.result
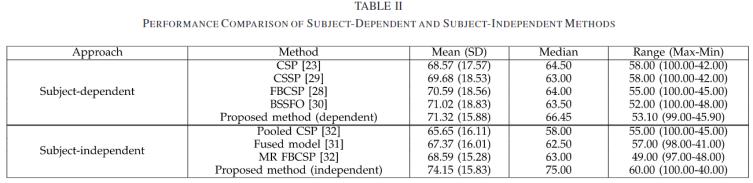
表2显示了各个方法在所有受试者中的平均解码准确率。subject-independent的方法的解码准确率分别为65.65%(±16.11),67.37%(±16.01),68.59%(±15.28),以及74.15%(±15.83),集合csp,融合模型,mr-fbcsp,以及建议的方法。在subject-independent前提下使用文中提出的模型进行多重比较测试,用bonferroni进行方差分析测试的结果是[f(3,212) = 2.9184, p = 0.0351]。subject-dependent的方法中,csp、cssp、fbcsp和bssfo的解码准确率分别为68.57%(±17.57)、69.68%(±18.53)、70.59%(±18.56)和71.02%(±18.83)。在依赖主体的方法和拟议方法的多重比较测试中,用bonferroni进行方差分析测试的结果是[f(4,265) = 0.7373, p = 0.5672]。
表2
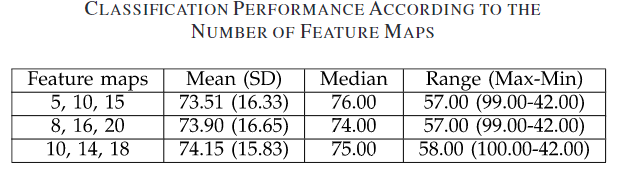
此外,作者还对cnn中的卷积核尺寸以及卷积的特征图数量进行了调整测试,结果如表3和表4
表3 卷积核尺寸消融实验结果
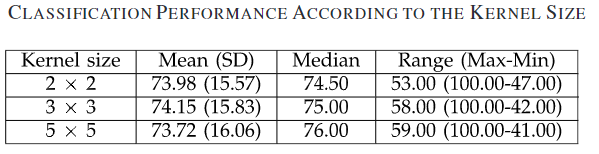
表4 特征图数量消融实验结果
6.discussion
由于缺乏一个大型的公共mi数据库,以前使用dl的研究只能在依赖主体的环境中工作。通过使用我们的大规模mi数据库,研究真正需要多少数据来开发一个可接受的与主体无关的dl网络模型(即训练cnn所需的训练样本数量是多少?) 我们的mi数据库包括大量受试者且每个受试者都进行了多次任务中。因此,该数据库包括各种大脑信号,这些信号代表了各个受试者的固有特征和不同时段的脑电图变化。在图6中,可以看出每次迭代都有巨大的性能变化。例如,当使用五个受试者时,第一次和第二次迭代的结果显示出分类性能的显著差异。这可以解释为不同受试者之间的数据存在明显的差异,因此,少量的训练样本既可以帮助也可以损害实际训练。这一点在现实世界中已经被其他研究者所证。因此如图6所示,所利用的训练样本数量越多,所能获得的分类性能就越好。
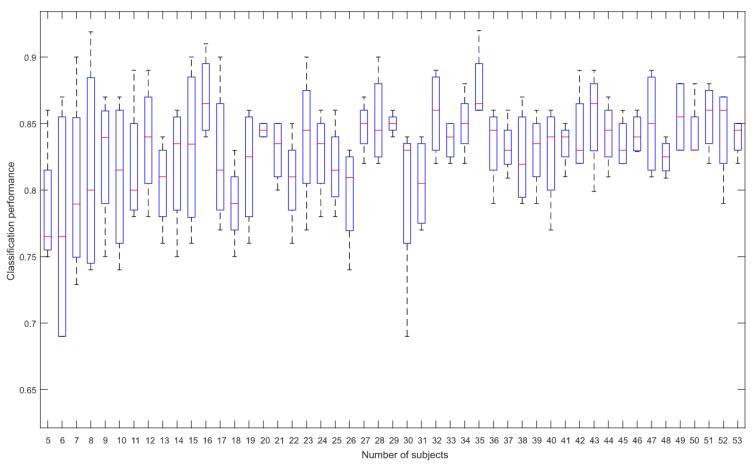
图6 受试者数量增加对发呢类准确率的影响(测试数据选择一个主体,本实验使用了20个频率指数。训练用的受试者组成以1为单位从n=5增加到n=53,每次迭代都是随机改变的。)
从这个角度来看,我们可以解释依赖主体和不依赖主体的环境中分类性能的差异,如表二所示。表二中的结果显示,虽然cnn在依赖主体的条件下和其他传统方法一样好,但在独立主体的条件下,它比传统方法好很多。图6清楚地表明,更多的训练样本有助于提高分类性能。在大数据集和dl的情况下,我们提出的方法都优于依赖于主体的方法。此外,在依赖主体的bci研究中,主要考虑对用户特定频段的调查,以提高解码准确性。一个突出的策略是随机地找到对个体受试者来说是最佳的多个频率范围。然而,从独立于受试者的bci角度来看,由于无法获得目标受试者的训练数据,很难找到或定义特定的频段。因此,我们包括在mi研究中广泛使用的标准频段(如μ节律和β节律)以及根据经验确定并与各频段重叠的额外频段。我们部署了大量的重叠频段的原因是,没有一个单一的频率范围对所有受试者都是最有鉴别力的。因此,我们决定使用由各种频段组成的滤波器组,以便从所有训练样本中提供更大的脑电图模式的多样性。。
7. conclusion
本文中,作者为基于mi的bci系统提出了一个subject-independent的cnn框架。光谱-空间输入生成被用来表示来自大规模mi数据库的一般大脑信号模式。实验结果表明,所提出的方法明显优于以前传统的subject-independent和subject-dependent方法。总之,这篇文章展示了所提出的特征表示与深度神经网络方法的卓越性能和有前途的潜力。本文可为subject-independent的bci的实际实施铺平道路。






