 690
690
 0
0
 2023-03-22
2023-03-22
 2023-03-22
2023-03-22
本篇学习报告介绍的论文题目是“high-resolution image reconstruction with latent diffusion models from human brain activity”。作者是yu takagi和shinji nishimoto,分别来自日本大阪大学和日本信息通信研究机构。该论文最初在2022年11月18日发表于biorxiv,随后在2023年2月28日上榜了2023 cvpr会议论文。
论文摘要
- 这篇论文提出了一种基于扩散模型(dm)的方法,从功能性磁共振成像(fmri)获取的人类大脑活动中重建高分辨率图像。
- 这种方法利用了一种潜在扩散模型(ldm),称为稳定扩散(stable diffusion)。这种模型降低了dm的计算成本,同时保持了它们的高生成性能。
- 这篇论文还通过研究ldm的不同组成部分(如图像的潜在向量z、条件输入c和去噪u-net的不同元素)与不同大脑功能之间的关系,来揭示ldm的内部机制。
- 这篇论文展示了该方法可以直接地从人类大脑活动中重建具有高保真度的高分辨率图像(512×512),而无需对复杂的深度学习模型进行任何额外的训练和微调。
- 这篇论文还从神经科学的角度对ldm的不同组成部分进行了定量解释。
- 总之,这篇论文提出了一种从人类大脑活动中重建图像的有前途的方法,并提供了一种理解dms的新框架。
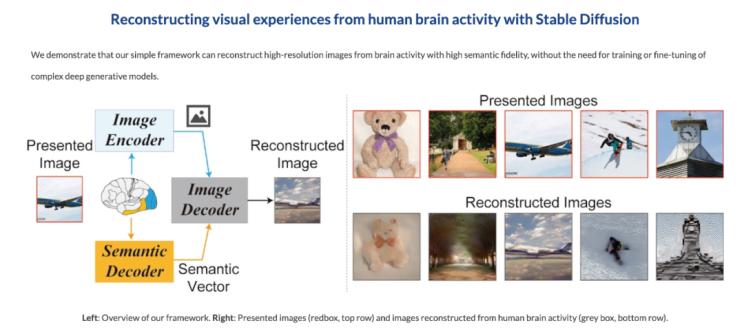
图1
方法概览
该研究的总体方法如下图 2所示。图 2(上)是该研究中使用的 ldm 示意图,其中,ε 表示图像编码器,d 表示图像解码器,τ 表示文本编码器(clip)。 图 2(中)是该研究的解码分析示意图。研究者分别从早期(蓝色)和高级(黄色)视觉皮层内的 fmri 信号中解码了呈现图像 (z) 和相关文本 c 的潜在表征。这些潜在表征被用作生成重建图像 x_zc 的输入。 图 2(下)是该研究的编码分析示意图。研究者构建了编码模型来预测来自 ldm 不同组成部分的 fmri 信号,包括 z、c 和 zc。
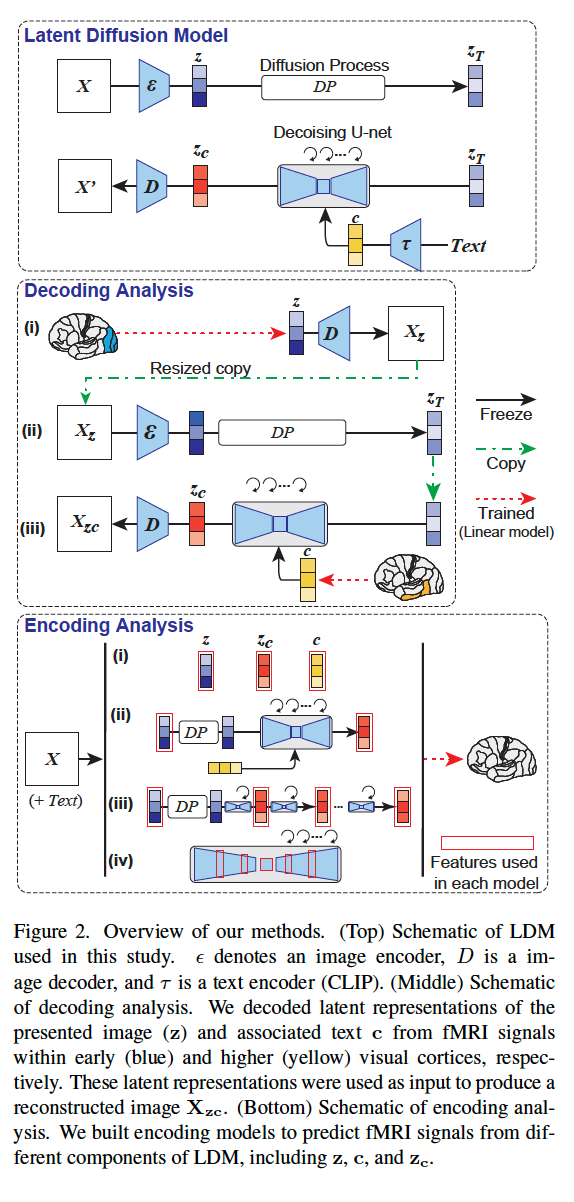
图2
解码
下图 3 展示了一个主体(subj01)的视觉重建结果。研究者为每个测试图像生成了五个图像,并选择了具有最高 psm 的图像。一方面,只用 z 重建的图像在视觉上与原始图像一致,但未能抓住其语义内容。另一方面,只用 c 重建的图像生成的图像具有很高的语义保真度,但在视觉上却不一致。最后,使用zc 重建的图像可以生成具有高语义保真度的高分辨率图像。

图 3
图 4 展示了所有测试者对同一图像的重建图像(所有图像都是用 zc 生成的)。总体来说,各测试者的重建质量是稳定和准确的。

图4
图 5 是定量评估的结果,结果表明,该研究方法不仅捕捉了低水平的视觉外观,而且还捕捉了原始刺激的高水平语义内容。
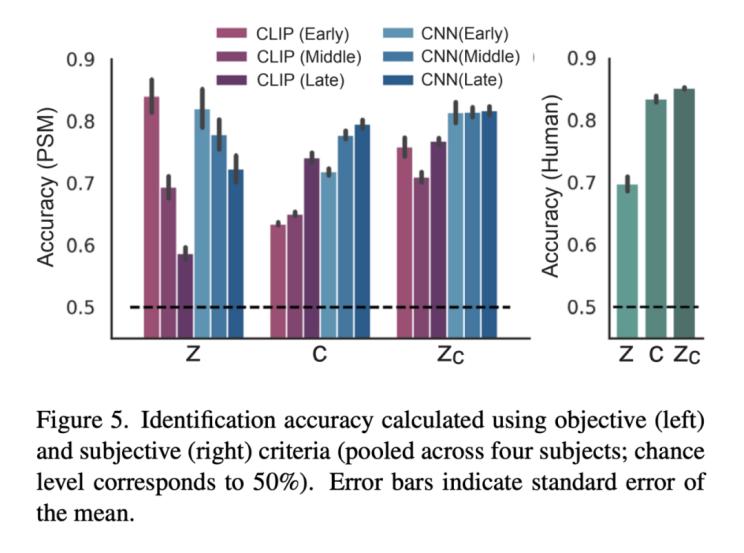
图5
编码模型
图 6 显示了编码模型对与 ldm 相关的三种潜像的预测精度:z,原始图像的潜像;c,图像文本注释的潜像;以及 zc,经过与 c 交叉注意力反向扩散过程后的 z 的加噪潜像表征。尽管这三个组成部分在大脑的视觉皮层产生了很高的预测性能,但它们显示出鲜明的对比。其中z在视觉皮层的后部,即早期视觉皮层具有较高的预测能力。在视皮层前部也有显著的预测价值,即较高的视皮层,但在其他区域的预测价值较小。另一方面,c在高级视觉皮层的预测性能最高。该模型在大范围的皮层上也表现出较高的预测性能。zc所携带的表示法与z非常相似,对早期视觉皮层表现出较高的预测性能。
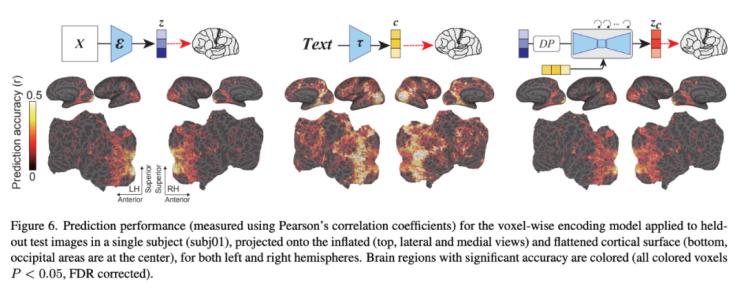
图6
图 7 显示,当加入少量的噪声时,z 对整个皮层的体素活动的预测比 zc 更好。有趣的是,当增加噪声水平时,zc 对高位视觉皮层内体素活动的预测优于 z,表明图像的语义内容逐渐被强调。

图7
在迭代去噪过程中,添加噪声的潜在表征如图8所示,在去噪过程的早期阶段,z 信号主导了 fmri 信号的预测。在去噪过程的中间阶段,zc 对高位视觉皮层内活动的预测比 z 好得多,表明大部分语义内容在这个阶段出现了。结果显示了 ldm 如何从噪声中提炼和生成图像。
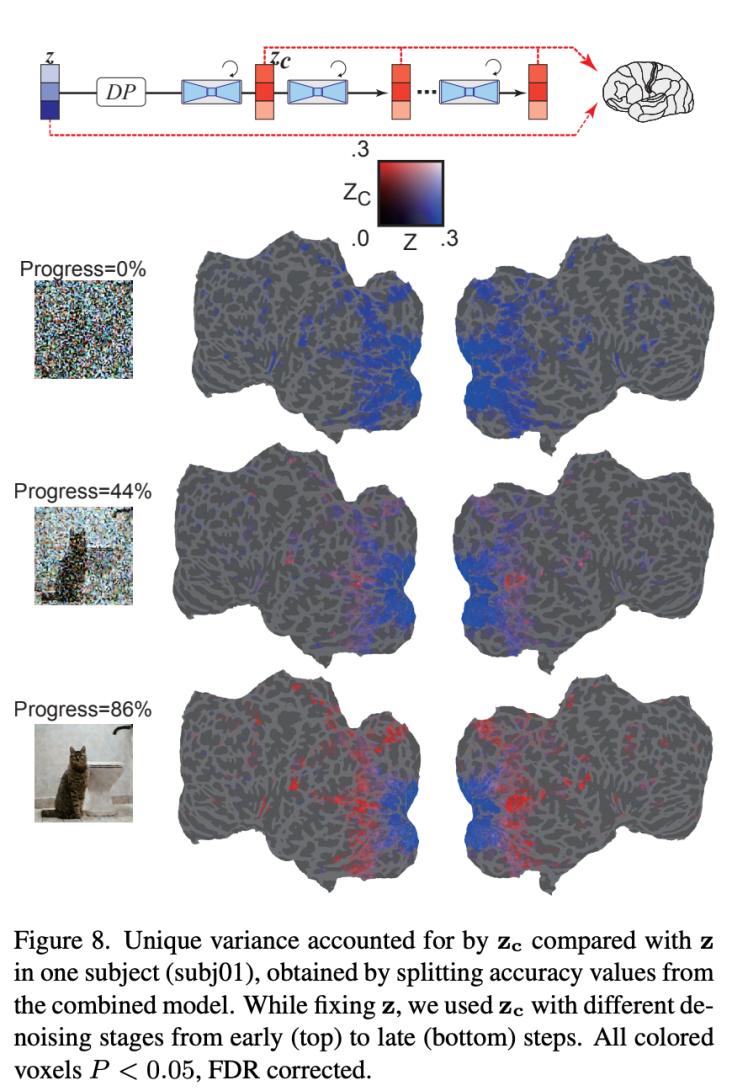
图8
最后,研究者探讨了 u-net 的每一层都在处理什么信息。图 9 显示了去噪过程的不同步骤(早期、中期、晚期)以及 u-net 不同层的编码模型的结果。在去噪过程的早期阶段,u-net 的瓶颈层(橙色)在整个皮层中产生了最高的预测性能。然而,随着去噪的进行,u-net 的早期层(蓝色)预测早期视觉皮层内的活动,而瓶颈层则转向对更高的视觉皮层的卓越预测能力。
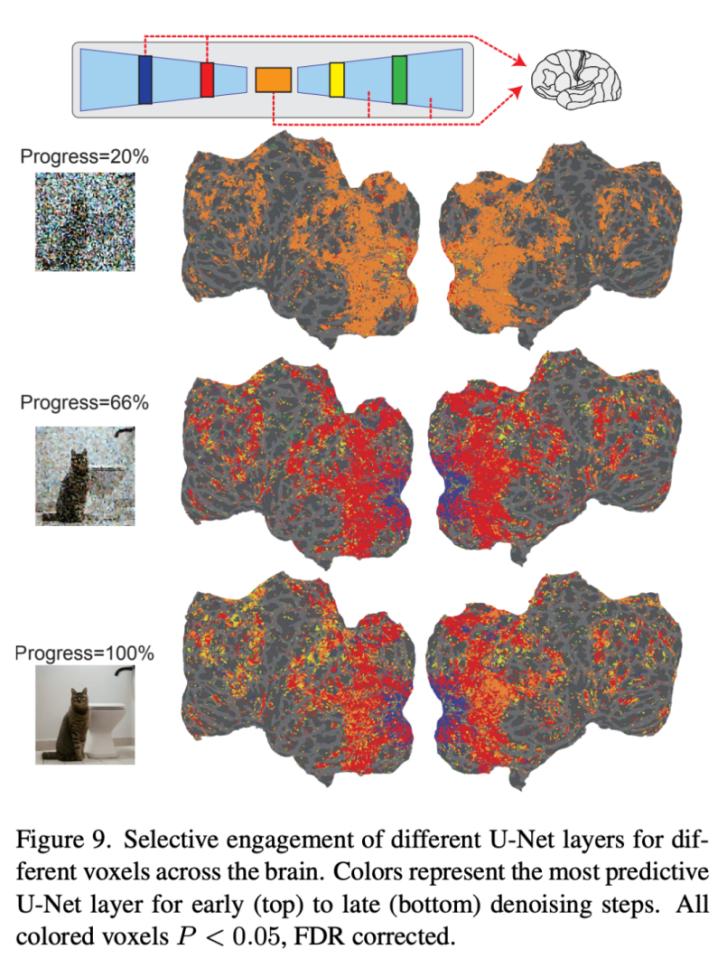
图9
结论
论文提出了一种新的基于ldm的视觉重建方法。表明可以从人脑活动中重建具有高语义保真度的高分辨率图像。与之前的图像重建研究不同,方法不需要对复杂的深度学习模型进行训练或微调:只需要从fmri到ldm内潜在表征的简单线性映射。
论文还通过构建编码模型为ldm的内部组件提供了定量解释。例如演示了整个逆扩散过程中语义内容的出现,执行了u-net的分层表征,并且提供了具有不同噪声级别的图像到图像转换的定量解释。尽管dm正在迅速发展,但对其内部过程仍然知之甚少。这项研究首次从生物学角度提供了定量解释。
同样这篇论文也存在一些局限性和未来改进的方向:
- fmri信号本身就存在噪声、失真、延迟等问题,可能影响重建结果的准确性和稳定性;
- 稳定扩散模型虽然降低了计算成本,但仍然需要大量时间和资源来生成高分辨率图像;
- 目前只使用了自然场景图片作为刺激材料,未考虑其他类型或复杂度的视觉内容;
- 目前只使用了单个受试者作为数据来源,未考虑个体差异或群体平均效应。
通过阅读这篇论文,我觉得这种方法在实际应用中有以下几个方面的价值:
- 它可以帮助我们更好地理解人类大脑如何表示和处理视觉信息,以及不同大脑区域之间的功能联系;
- 它可以为神经科学和计算机视觉之间的交叉研究提供一个新的框架和工具,促进两个领域的相互启发和进步;
- 它可以为一些实际应用提供支持,例如:
- 通过重建梦境或想象中的场景,增强人们的创造力和表达能力;
- 通过重建失明或受损人士的视觉体验,帮助他们恢复或改善视觉功能;
- 通过重建犯罪嫌疑人或证人的视觉记忆,辅助司法调查和判断。
论文地址:
项目地址:
撰稿人:黄伟聪
审稿人:梁艳






