
 151
151
 6
6
 0
0
 2023-07-31 08:07:01
2023-07-31 08:07:01
 2023-07-31
2023-07-31
可度量数量信息
(measurable quantitative information)
郝天永(华南师范大学)
王海涛 (中国标准化研究院)
曹馨宇 (中国标准化研究院)
开篇导语
从医院电子病历到上市公司文本报告,从区域教育治理到金融风险防控,不同领域不同语言的自然文本常常蕴含大量的数量信息,这些数量信息的分析和理解是数字资源利用的重要基础之一。可度量数量信息(measurable quantitative information,mqi)以广泛出现的数量信息为基础,表达了实体、数量及其关系的综合信息,如“预期城镇新增就业不低于1186万人”、 “公司净利润在1300至2000万之间”、“7% of hba1c level at admission but 10% after 2 days”。海量可度量数量信息的自动分析及结构化表示,对自然语言处理技术、语言资源建设管理、数据汇聚计算、企业竞争情报分析、乃至数字经济都具有重要现实意义。
infobox:
中文名:可度量数量信息
外文名:measurable quantitative information
简写:mqi
学科:自然语言处理
实质:描述了实体、数值、单位及其之间关系
基本简介:
可度量数量信息的基础元素包括实体(entity)、数值/区间(numeral/range)、计量单位(unit)和连接关系(relations)。根据iso国际标准[1],其中数值和计量单位构成可度量数量信息的数量(measure),连接关系包括依赖关系(dependency link)和比较关系(comparison link),依赖关系表示实体与相关数量属性相关性而比较关系表示实体的实际数量和描述数量的比较性。从原始文本中通过信息抽取系统对实体和相关数量属性进行识别和关联后,以xml、或四元组、或多元组的形式进行结构化表示。
可度量数量信息抽取是一项从半结构化和非结构化文本中提取和组织可度量数量信息的任务,属于自然语言处理的信息抽取研究领域。可度量数量信息抽取任务可以拆分为可度量信息识别任务和可度量信息关联任务。识别任务从原始文本数据中提取实体、数值和计量单位等基础信息,关联任务将这些基础信息进行匹配和关联,生成结构化的可度量数量信息。以语句 “白细胞不低于14.0x10^9/l” 为例,其中 “白细胞” 为实体,“14.0x10^9” 为数值,“l” 为计量单位, 数值与计量单位的组合 “14.0x10^9/l” 为数量,蕴含的比较关系(数量修饰符)为 “大于等于”,其简单的结构化可度量数量信息可表示为:“{ entity: 白细胞, numeral: 14.0x10^9, unit: l, relator: 不低于, comparison: 大于等于}”,如图1所示。
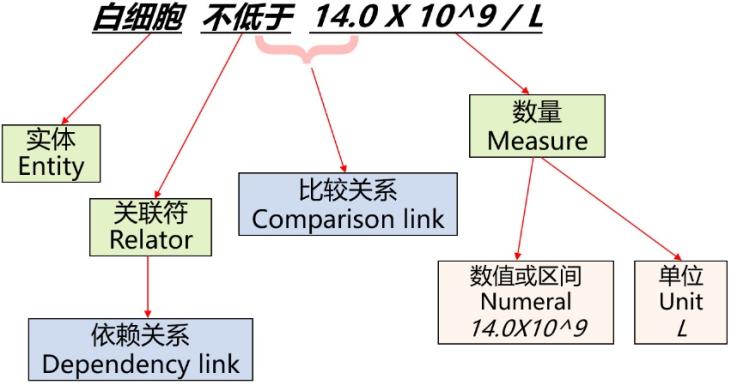
图1. 一个可度量数量信息的构造示例
可度量数量信息不仅可用于通用或领域知识图谱构建、属性比对、数值汇聚,特别是在临床、生物医学、化学和材料、金融等量化信息高度集中的领域,可度量数量信息的抽取成为定量分析应用的关键技术基础之一。
背景与挑战:
随着互联网的发展和数据规模的快速增长,一方面有组织的可用的结构化的可度量数量信息数据库极度稀缺,另一方面海量的可度量数量信息存于非结构化文本中无法被有效利用,中间存在的巨量可度量数量信息缺口急需填补。作为医学领域的重要信息,可度量数量信息有助于临床决策支持、疾病风险预测和疾病监测。例如,在临床试验纳排标准文本中的可度量数量信息占比超过40%,低精度的可度量数量信息抽取是导致药物剂量分析与临床试验资格标准认定等研究的瓶颈。
尽管近年来可度量数量信息抽取已经得到了工业界和自然语言处理研究人员关注,但它仍然面临许多挑战,例如:
(1)数量属性的表达具有多样性。数值可以用无数种不同的语言形式来表达,不同领域的计量单位也有不同的书写方式。此外,复杂的可度量数量信息可能包含多个数量属性[2],甚至需要解析公式或表达式以获取数值。因此,将数值和计量单位识别完整并准确关联成为一个复杂的问题。
(2)目前的信息抽取系统通常基于句子进行抽取,一句话所给出的上下文往往过于狭窄,而语义相关的上下文信息可能与数值所在的文本位置相距较远,导致模型无法理解可度量数量信息的上下文[3],进一步影响实体、数值、计量单位和比较关系的抽取和标准化。
(3)原始文本数据复杂多样,例如,临床报告和笔记等医学文本通常以复杂和非正式的方式书写[4],其他文档类型,如产品数据表,大量使用表格和技术图纸来传达信息。 此外,将原始文本数据转换成机器可读数据的过程也会产生噪声。
(4)可度量数量信息模型的推理能力需要加强。当信息因简短而被省略时,当处理像 "光速"这样的常数时,为了推断一个区间是否包括或不包括其端点时,或者在处理相对于标准的数量时(例如,"正常上限的1.15倍")[5]。此外,计量单位省略也经常发生[6]。这些需要大量领域知识进行支撑,帮助模型理解定量表述并进一步完成数量属性的推断。
研究概况:
可度量数量信息抽取的发展主要经历了五个阶段:(1)基于手工的方法,(2)基于规则和模式匹配的方法,(3)基于传统机器学习的方法,(4)基于深度学习的方法,(5)基于预训练语言模型的方法。
在早期阶段,关于可度量数量信息抽取的研究大多数是基于规则的方法。基于规则的方法以规则、模式和关键词匹配、本体匹配或字典匹配的组合为主。除了字符串匹配之外,模式通常涉及基于词性(part-of-speech tagging,pos)标签的句法规则。例如,valx[5]使用umls 元词典等外部知识设计启发式规则和领域知识来辅助提取二型糖尿病的相关数值信息。liu 等人[7] 提出了一个基于规则的信息提取系统,从临床记录中提取带有时间信息的实验室测试结果,其中,数量和单位的提取由已有的数量、单位和时间表达标记器支持。liu等人[8] 结合了规则和模式匹配的方法用于提取临床定量信息。基于规则的方法通常具有更高的准确率,较低的召回率,需要专家投入大量时间手动设计规则。为了平衡准确率和召回率,基于特征工程的机器学习方法被提出用于提取可度量数量信息并且被广泛应用于针对科学出版物和网络数据文本的抽取系统。例如,gruss等人[9]将朴素贝叶斯分类器应用于数值表达式的抽取及分类。berrahou 等人[10] 则是利用 j48 决策树、支持向量机(support vector machines)、朴素贝叶斯 (naive bayes)、判别性多义朴素贝叶斯 (discriminative multinominal naive bayes) 等多个分类器对科学文档中的单位进行抽取。基于机器学习的模型性能对特征工程依赖性较高,基于人工的特征方法需要消耗大量的时间、人力和物力。
由于在自动特征提取方面的优势,基于深度学习的可度量数量信息抽取方法发展迅速。思路主要是使用iob等标记方案将实体、数值和单位的识别转换为序列标记问题,基于conditional random field (crf) [11] 构建抽取模型。例如,li 等人[12] 将医学词典和词性信息结合到双向长短期记忆递归神经网络(bi-lstm-crf)中以改进临床命名实体识别。liu等人[13] 提出了融合领域知识信息和位置特征的bi-lstm-crf模型,实验验证了特征增强的双向长短期记忆递归神经网络在临床可度量数量信息抽取上的有效性。foppiano等人[14] 提出了基于crf的grobid-quantities 系统,该系统用于识别和标准化科学和技术文件中的物理测量。不同于上述针对特定领域研发的系统,saha 等人[15] 设计并发布了bonie, 一个用于抽取包含数值和计量单位短语等多元组信息的开放式数值关系提取器。
近年来,随着预训练语言模型(pre-trained language models, plms)的出现,如基于transformer的双向编码表示 (bidirectional encoder representations from transformers, bert) [16],已成为许多自然语言处理任务的基本支撑。例如,zhang等人[17] 使用bert预训练的单词嵌入作为bi-lstm-crf的输入特征,有效提升了乳腺癌的临床信息识别模型的性能。avram等人[18] 使用roberta crf模型对iob序列标签进行识别,并通过将跨度提取视为多轮问题回答来提取相关的可度量实体、属性和限定词。kohler 等人[19] 采用gpt-3[20]进行小样本学习(few-shot learning),但实验结果表明针对可度量数量信息抽取的小样本学习方法并不能有效提升模型性能。
未来发展:
由于实体与数量信息表述的复杂性, 从非结构化文档中精准抽取可度量数量信息仍然是一个重要的挑战。未来的可度量数量信息抽取的研究趋势主要有以下三个方向:
(1)可度量数量信息抽取模型训练需要更多相关高质量数据集。不同领域的计量单位和实体存在差异性,目前仍然存在标注数据不足的问题。涵盖数量及其上下文的更广泛的数据集可以极大地改善可度量数量信息抽取模型的性能。
(2)增强模型的数值推理能力以提升可度量数量信息抽取系统的性能。例如,在预处理过程中改变所有数值的表示形式以提高模型性能[21],用数值的特殊表示扩展语言模型以提高数值推理能力[22]。
(3)抽取系统的发展需要优化模型对文本上下文的利用。目前,许多系统在句子级别上进行抽取,或者在固定的标记限制的局部文本进行抽取,缺少考虑文本上下文并结合其他模式信息的可度量数量信息提取系统。
参考文献






